Adaptive sampling
Adaptive sampling [a1] is a probabilistic algorithm invented by M. Wegman (unpublished) around 1980. It provides an unbiased estimator of the number of distinct elements (the "cardinality" ) of a file (a sequence of data items) of potentially large size that contains unpredictable replications. The algorithm is useful in data-base query optimization and in information retrieval. By standard hashing techniques [a3], [a6] the problem reduces to the following.
A sequence 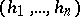 of real numbers is given. The sequence has been formed by drawing independently and randomly an unknown number
of real numbers is given. The sequence has been formed by drawing independently and randomly an unknown number 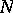 of real numbers from
of real numbers from 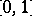 , after which the elements are replicated and permuted in some unknown fashion. The problem is to estimate the cardinality
, after which the elements are replicated and permuted in some unknown fashion. The problem is to estimate the cardinality 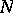 in a computationally efficient manner.
in a computationally efficient manner.
Three algorithms can perform this task.
1) Straight scan computes incrementally the sets 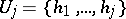 , where replications are eliminated on the fly. (This can be achieved by keeping the successive
, where replications are eliminated on the fly. (This can be achieved by keeping the successive  in sorted order.) The cardinality is then determined exactly by
in sorted order.) The cardinality is then determined exactly by 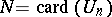 but the auxiliary memory needed is
but the auxiliary memory needed is 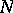 , which may be as large as
, which may be as large as  , resulting in a complexity that is prohibitive in many applications.
, resulting in a complexity that is prohibitive in many applications.
2) Static sampling is based on a fixed sampling ratio 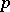 , where
, where 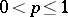 (e.g.,
(e.g., 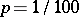 ). One computes sequentially the samples
). One computes sequentially the samples 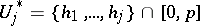 . The cardinality estimate returned is
. The cardinality estimate returned is 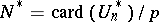 . The estimator
. The estimator 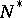 is unbiased and the memory used is
is unbiased and the memory used is 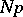 on average.
on average.
3) Adaptive sampling is based on a design parameter 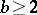 (e.g.,
(e.g., 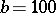 ) and it maintains a dynamically changing sampling rate
) and it maintains a dynamically changing sampling rate 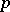 and a sequence of samples
and a sequence of samples 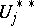 . Initially,
. Initially, 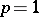 and
and 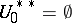 . The rule is like that of static sampling, but with
. The rule is like that of static sampling, but with 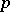 divided by
divided by  each time the cardinality of
each time the cardinality of 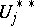 would exceed
would exceed 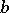 and with
and with 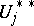 modified accordingly in order to contain only
modified accordingly in order to contain only 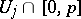 . The estimator
. The estimator 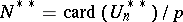 (where the final value of
(where the final value of 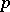 is used) is proved to be unbiased and the memory used is at most
is used) is proved to be unbiased and the memory used is at most 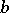 .
.
The accuracy of any such unbiased estimator 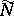 of
of 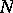 is measured by the standard deviation of
is measured by the standard deviation of 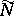 divided by
divided by 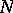 . For adaptive sampling, the accuracy is almost constant as a function of
. For adaptive sampling, the accuracy is almost constant as a function of 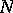 and asymptotically close to
and asymptotically close to
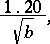 |
a result established in [a1] by generating functions and Mellin transform techniques. An alternative algorithm, called probabilistic counting [a2], provides an estimator 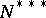 of cardinalities that is unbiased only asymptotically but has a better accuracy, of about
of cardinalities that is unbiased only asymptotically but has a better accuracy, of about 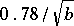 .
.
Typically, the adaptive sampling algorithm can be applied to gather statistics on word usage in a large text. Well-designed hashing transformations are then known to fulfill practically the uniformity assumption [a4]. A general perspective on probabilistic algorithms may be found in [a5].
References
| [a1] | P. Flajolet, "On adaptive sampling" Computing , 34 (1990) pp. 391–400 |
| [a2] | P. Flajolet, G.N. Martin, "Probabilistic counting algorithms for data base applications" J. Comp. System Sci. , 31 : 2 (1985) pp. 182–209 |
| [a3] | D.E. Knuth, "The art of computer programming" , 3. Sorting and Searching , Addison-Wesley (1973) |
| [a4] | V.Y. Lum, P.S.T. Yuen, M. Dodd, "Key to address transformations: a fundamental study based on large existing format files" Commun. ACM , 14 (1971) pp. 228–239 |
| [a5] | R. Motwani, P. Raghavan, "Randomized algorithms" , Cambridge Univ. Press (1995) |
| [a6] | R. Sedgewick, "Algorithms" , Addison-Wesley (1988) (Edition: Second) |
Adaptive sampling. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Adaptive_sampling&oldid=45023