Computational algorithm
An exactly defined specification of the operations to be carried out on data, by means of which it is possible, using a discrete-operation digital computer, to convert a certain amount of data (input data) into a certain amount of other data (output data) by performing a finite number of operations. A computational algorithm is realized in the form of a computational process, i.e. as a finite sequence of states of a real computer, discretely distributed in time, the real computer — unlike an abstract computer — having a restricted rate of performance of the operations, a restricted number of digit places to form a number and a restricted storage capacity.
If a computational algorithm and a computer are both given, the computational process is strictly deterministic, that is, to the given input data correspond, in a perfectly determinate manner: a sequence of computer operations; a sequence of computer states; output data. A computational algorithm is called linear if the sequence of operations of the computer is independent of the input data, and is called non-linear otherwise.
The object of operations of the computer are data in the form of machine words, which are interpreted as machine numbers, machine commands, etc. Machine numbers usually constitute a finite bounded set 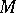 of numbers, located in the machine interval
of numbers, located in the machine interval 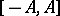 and written down in the digit frame of the machine, the base
and written down in the digit frame of the machine, the base  being given; here
being given; here 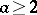 is some natural number and
is some natural number and  is the highest machine number (the machine infinity). As a result, machine numbers are subject to constraints both as regards the number of significant digits and as regards the absolute value. A given computer may work with various sets
is the highest machine number (the machine infinity). As a result, machine numbers are subject to constraints both as regards the number of significant digits and as regards the absolute value. A given computer may work with various sets  , corresponding to various bases, various frames and various machine intervals.
, corresponding to various bases, various frames and various machine intervals.
A machine command is a machine word which contains information about the operation (e.g. an arithmetical operation) and about the operands (the objects on which the operation is to be performed, and the result of the operation). An arithmetical operation on two machine numbers may produce a result lying outside the set 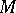 for two reasons: the number of significant digits is larger than permitted or the value itself is larger than the permissible value of the machine number. In the former case the result is rounded off, which brings back the result into
for two reasons: the number of significant digits is larger than permitted or the value itself is larger than the permissible value of the machine number. In the former case the result is rounded off, which brings back the result into 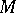 , but which renders the operation inexact and results in a loss of accuracy. The latter case brings the computer to a stop (a machine-breakdown).
, but which renders the operation inexact and results in a loss of accuracy. The latter case brings the computer to a stop (a machine-breakdown).
The combination of an arithmetical operation on two machine numbers followed by a rounding-off operation is called a quasi-operation. The set 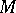 together with the set of quasi-operations defined over it forms a closed system
together with the set of quasi-operations defined over it forms a closed system 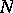 but, unlike in the case of a field of real numbers,
but, unlike in the case of a field of real numbers, 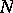 is not a field. The system
is not a field. The system 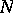 depends on the choice of the computer.
depends on the choice of the computer.
A real computational algorithm consists of two parts:
1) an abstract (or a proper) computational algorithm applicable to mathematical objects (elements of finite-dimensional vector spaces, fields, algebraic systems, functional systems, etc.) which is independent of the particular computer used and which may be written down in conventional mathematical terms or in some algorithmic language;
2) a program, i.e. a collection of machine commands describing the computational algorithms, organizing the realization of the computational process in the given computer.
The first part of the computational algorithm is the initial part which passes into the second part with the aid of various programming methods. A computational algorithm contains a number of control parameters, which remain indefinite in the first part, form a fixed part of the program, fully determine the computational process, and ensure the adaptation of its first part to a given computer.
A computational algorithm processes the numerical and the symbolic information and usually involves a loss of information and of accuracy. The loss of accuracy is the result of several errors which appear at the various stages in the computation: erroneous models, approximations, input data, and rounding-off operations. Erroneous models are the result of the approximate nature of a mathematical description of a real process. The errors in the input data may originate from errors in the observation, in the measurements, etc., as well as from the rounding off of the input information. The overall error originating from the model employed and from the input data is sometimes referred to as the inevitable error. The approximation error results from considering the abstract computational algorithm as some discrete model, which usually approximates a continuous model. In certain cases the abstract computational algorithm itself becomes an independent discrete model which is not juxtaposed with any other model; in such a case it is meaningless to talk about an approximation error. Rounding-off errors may be encountered in a real computational process only, and will depend on the choice of the computer. If the input data and the abstract computational algorithm are given, the intermediate and the output data produced by the computer depend on the choice of the computer and its mode of operation (computation with single and with double accuracy). An abstract computational algorithm permits equivalent transformations which, for given input data, may replace the intermediate data, while leaving the final result unchanged. A computational algorithm which corresponds to two different equivalent representations of an abstract computational algorithm may — for a given computer and given input data — yield distinct final results.
In addition to accuracy, a computational algorithm must also have the property of stability. Stability is defined as that property of a computational algorithm which makes it possible to estimate the rate of build-up of the overall computational error. There are various grades of stability (or instability), based on the determination of the initial rounding-off error and the overall computational error in different norms. If the computational algorithm consists solely of a sequence of linear recurrence relations, its stability is defined in terms of the norms of finite-dimensional matrices on finite-dimensional vector spaces. The property of stability is determined both by the structure of the abstract computational algorithm and by the effect of rounding-off errors. Thus, the stability of the iterative process 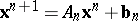 , where the matrix
, where the matrix 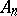 is computed as well, will depend on the effect of the rounding-off errors in the matrix coefficients on the norm of the matrix. Rounding-off errors included in the coefficients of various equations and operators perturb the mathematical model of the abstract computational algorithm and may be regarded, in that sense, as model errors as well. The better the stability of a given abstract computational algorithm, the less will the results of the computations depend on the choice of the computer or on the equivalent representations of the algorithm.
is computed as well, will depend on the effect of the rounding-off errors in the matrix coefficients on the norm of the matrix. Rounding-off errors included in the coefficients of various equations and operators perturb the mathematical model of the abstract computational algorithm and may be regarded, in that sense, as model errors as well. The better the stability of a given abstract computational algorithm, the less will the results of the computations depend on the choice of the computer or on the equivalent representations of the algorithm.
Another property, which is particularly important in large-scale calculations, is the economy of the computational algorithm, the measure of which is the machine time which must be spent in order to obtain a pre-set accuracy in the calculation. Economic computational algorithms have found extensive use in problems of mathematical physics (see, for example, Fractional steps, method of). An important task in the theory of computational algorithms is their optimization.
A typical feature in the construction of a computational algorithm is control of accuracy. Such a control can be realized indirectly by increasing the stability and the order of approximation of the algorithm, by changing its parameters (internal convergence), by comparison of two numerical solutions of the same problem produced by different computational algorithms, by an application of tests, etc. A direct control of accuracy is performed if two-sided estimates (or at least one-sided estimates) of the result of the computation are available (cf. Two-sided estimate). Theoretical estimates of this kind are not always possible or effective, since the limits of the deviation of the numerical solution from the true value yielded by such estimates may not be sufficiently accurate. A widespread method is interval analysis, in which confidence bounds of the computed magnitudes may be obtained in the course of the computations.
The differences between the results yielded by the abstract and the real computational algorithm are due to rather complicated relations between their parameters. Thus, in an abstract computational algorithm the accuracy  for a convergent iterative process is usually higher, the larger the number
for a convergent iterative process is usually higher, the larger the number  of iterations. In a real computational algorithm this situation may change as a result of the effect of rounding-off errors and, starting from some moment, the difference between the
of iterations. In a real computational algorithm this situation may change as a result of the effect of rounding-off errors and, starting from some moment, the difference between the  -th iteration and the accurate solution may no longer decrease.
-th iteration and the accurate solution may no longer decrease.
Generally speaking, an abstract computational algorithm is compiled irrespective of the choice of a specific computer, the configuration of the latter being allowed for only indirectly — as the approximation and stability properties of the algorithm. Thus, if the operational speed of the machine is high but its storage capacity is low, it is expedient to use economical, absolutely stable, highly accurate schemes in solving partial differential equations. The advent of computers with processors acting in parallel has led to the development of parallel algorithms and parallel programming. In parallel programming the processed numerical data are subdivided into parts (sub-blocks) and these are independently processed by the respective processors; there is an exchange of information between the sub-blocks, and the time lost during this interchange is much shorter than the gain in time obtained by deparallelization of the calculation. The use of parallel computers is thus desirable, since the speed of the computations is greatly increased, especially in problems involving large-scale calculations.
The large variety of available computers results in a variety of programs realizing the same abstract computational algorithm. Comparison of these programs is laborious; hence the special importance of the adaptation problem, i.e. a fast and, if possible, automatic translation of the program for a given abstract computational algorithm from one computer to another (cf. Programming).
Computational algorithm. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Computational_algorithm&oldid=14724