Informant
The gradient of the logarithmic likelihood function. The concept of the informant arose in so-called parametric problems in mathematical statistics. Suppose one has the a priori information that an observed random phenomenon can be described by a probability distribution  from a family
from a family  , where
, where  is a numerical or vector parameter, but for which the true value of
is a numerical or vector parameter, but for which the true value of  is unknown. The observation (series of independent observations) made led to the outcome
is unknown. The observation (series of independent observations) made led to the outcome  (series of outcomes
(series of outcomes  ). It is required to estimate
). It is required to estimate  from the outcome(s). Suppose that the family
from the outcome(s). Suppose that the family  is given by a family of densities
is given by a family of densities  with respect to a measure
with respect to a measure  on the space
on the space  of outcomes of observations. If
of outcomes of observations. If  is discrete, then the probabilities
is discrete, then the probabilities 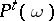 itself can be taken for
itself can be taken for  . For
. For 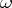 fixed,
fixed,  , as a function of
, as a function of 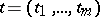 , is called a likelihood function, and its logarithm is called a logarithmic likelihood function.
, is called a likelihood function, and its logarithm is called a logarithmic likelihood function.
For smooth families the informant can conveniently be introduced as the vector
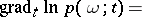 |
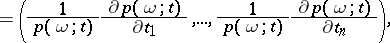 |
which, unlike the logarithmic likelihood function, does not depend on the choice of 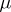 . The informant contains all essential information, both that obtained from the observations, as well as the a priori information, for the problem of estimating
. The informant contains all essential information, both that obtained from the observations, as well as the a priori information, for the problem of estimating  . Moreover, it is additive: For independent observations, i.e. when
. Moreover, it is additive: For independent observations, i.e. when
 |
the informants are summed:
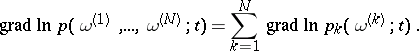 |
In statistical estimation theory the properties of the informant as a vector function are important. Under the assumptions that the logarithmic likelihood function is regular, in particular, twice differentiable, that its derivatives are integrable and that differentiation by the parameter may be interchanged with integration with respect to the outcomes, one has
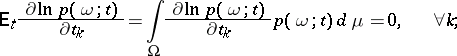 |
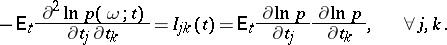 |
The covariance matrix 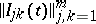 is called the information matrix. An inequality expressing a bound on the exactness of statistical estimators for
is called the information matrix. An inequality expressing a bound on the exactness of statistical estimators for  can be given in terms of this matrix.
can be given in terms of this matrix.
When estimating 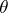 by the maximum-likelihood method, one assigns to the observed outcome
by the maximum-likelihood method, one assigns to the observed outcome 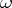 (or series
(or series 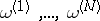 ) the most likely value
) the most likely value 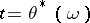 , i.e. one maximizes the likelihood function and its logarithm. At an extremal point the informant must vanish. However, the likelihood equation that arises,
, i.e. one maximizes the likelihood function and its logarithm. At an extremal point the informant must vanish. However, the likelihood equation that arises,
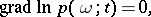 |
can have roots 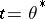 , corresponding to maxima of the logarithmic likelihood function that are only local (or to minima); these must be discarded. If, in a neighbourhood of
, corresponding to maxima of the logarithmic likelihood function that are only local (or to minima); these must be discarded. If, in a neighbourhood of 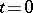 ,
,
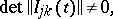 |
then the asymptotic optimality of the maximum-likelihood estimator  follows from the listed properties of the informant, as the number
follows from the listed properties of the informant, as the number  of independent observations used grows indefinitely.
of independent observations used grows indefinitely.
References
| [1] | S.S. Wilks, "Mathematical statistics" , Wiley (1962) |
Informant. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Informant&oldid=47347