Coding and decoding
The process of representing information in a definite standard form and the inverse process of recovering the information in terms of such a representation of it. In the mathematical literature an encoding (coding) is a mapping of an arbitrary set $ A $
into the set of finite sequences (words) over some alphabet $ B $,
while the inverse mapping is called a decoding. Examples of an encoding are: the representation of the natural numbers in the $ r $-
ary number systems, where each number $ N = 1, 2 \dots $
is made to correspond to the word $ b _ {1} \dots b _ {l} $
over the alphabet $ B _ {r} = \{ 0 \dots r - 1 \} $
for which $ b _ {1} \neq 0 $
and $ b _ {1} r ^ {l-1} + \dots + b _ {l} = N $;
the conversion of English texts by means of a telegraphic code into sequences consisting of the transmission of pulses and pauses of various lengths; and the mapping applied in writing down the digits of a (Russian) postal index (see Fig.a and Fig.b). In this latter case, there corresponds to each decimal digit a word over the alphabet $ B _ {2} = \{ 0 , 1 \} $
of length 9 in which numbers referring to a line that is to be used are marked by the symbol $ 1 $.
(For example, the word $ 110010011 $
corresponds to the digit $ 5 $.)
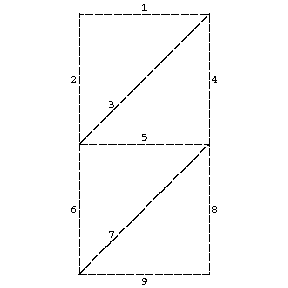
Figure: c022890a
Figure: c022890b
The investigation of various properties of coding and decoding and the construction of encodings that are effective in some sense and possess specified properties constitute the subject matter of coding theory. Usually, a criterion for the effectiveness of an encoding is in some way or other tied up with the minimization of the length of the code words (images of the elements of the set $ A $), and the specified properties of the coding relate to the guarantee of a given level of noise immunity, to be understood in some sense or other. In particular, noise immunity means the possibility of unique decoding in the absence of, or at a tolerable level of, distortion of the code words. Besides noise immunity, a number of additional requirements may be imposed on the code. For example, in the choice of an encoding for the digits of a postal code, an agreement with the ordinary way of writing digits is necessary. As additional requirements, restrictions are often applied relating to the allowed complexity of the scheme effecting the coding and decoding. The problems in coding theory were in the main created under the influence of the theory of information transmission as developed by C. Shannon [1]. A source of new problems in coding theory is provided by the creation and perfection of automated systems of gathering, storage, transmission, and processing of information. The methods of solving problems in coding theory are mainly combinatorial, probability-theoretic and algebraic.
An arbitrary coding $ f $ of a set (alphabet) $ A $ by words over an alphabet $ B $ can be extended to the set $ A ^ {*} $ of all words over $ A $( messages) as follows:
$$ f ( a _ {1} \dots a _ {k} ) = f ( a _ {1} ) \dots f ( a _ {k} ) , $$
where $ a _ {i} \in A $, $ i = 1 \dots k $. Such a mapping $ f : A ^ {*} \rightarrow B ^ {*} $ is called a letter-by-letter encoding of the messages. A more general class of encodings of messages is found by automated encoding realized by initial asynchronous automata (cf. Automaton), which deliver at each instant of time some (possibly empty) word over the alphabet $ B $. The importance of this generalization consists in the fact that the automaton realizes, in different states, different encodings of the letters of the alphabet of the messages. A letter-by-letter encoding is an automaton encoding realized by a single-state automaton. One of the branches of coding theory is the study of the general properties of a coding and the construction of algorithms for recognizing these properties (see Coding, alphabetical). In particular, necessary and sufficient conditions have been found for automated and letter-by-letter encodings in order that 1) the decoding be single-valued; 2) there exists a decoding automaton, that is, an automaton effecting the decoding with a certain bounded delay; or 3) there exists a self-adjusting decoding automaton (making it possible to eliminate in a limited amount of time the effect of a mistake in the input sequence or in the functioning of the automaton itself).
The majority of problems in coding theory reduces to the study of finite or countable sets of words over an alphabet $ B _ {r} $. Such sets are called codes. In particular, there corresponds to each single-valued encoding $ f : B _ {m} \rightarrow B _ {r} ^ {*} $( and letter-by-letter encoding $ f : B _ {m} ^ {*} \rightarrow B _ {r} ^ {*} $) a code $ \{ f ( 0) \dots f ( m - 1 ) \} \subset B _ {r} ^ {*} $. One of the basic assertions in coding theory is that the condition of injectivity of a letter-by-letter encoding $ f : B _ {m} ^ {*} \rightarrow B _ {r} ^ {*} $ imposes the following restrictions on the lengths $ l _ {i} = l _ {i} ( f ) $ of the code words $ f ( i) $:
$$ \tag{1 } \sum_{i=0}^ {m-1} r ^ {- l _ {i} } \leq 1 . $$
The converse statement also holds: If $ ( l _ {0} \dots l _ {m-1} ) $ is a set of natural numbers satisfying (1), then there exists a one-to-one letter-by-letter encoding $ f : B _ {m} ^ {*} \rightarrow B _ {r} ^ {*} $ such that the word $ f ( i) $ has length $ l _ {i} $. Furthermore, if the numbers $ l _ {i} $ are increasingly ordered, then one can take for $ f ( i) $ the first $ l _ {i} $ symbols after the decimal point of the expansion of $ \sum_{j=0}^ {i-1} r ^ {- l _ {j} } $ in an $ r $- ary fraction (Shannon's method).
The most definitive results in coding theory relate to the construction of effective one-to-one encodings. The constructions described here are used in practice for the compression of information and access of information from the memory. The concept of effectiveness of an encoding depends on the choice of the cost criterion. In the definition of the cost $ L ( f ) $ of a one-to-one letter-by-letter encoding $ f : B _ {m} ^ {*} \rightarrow B _ {r} ^ {*} $ it is assumed that there corresponds to each number $ i \in B _ {m} $ a positive number $ p _ {i} $ and that $ P = \{ p _ {0} \dots p _ {m-1} \} $. The following versions of a definition of the cost $ L ( f ) $ have been investigated:
1) $ L _ {mean } ( f ) = \sum_{i=0}^ {m-1} p _ {i} l _ {i} $,
2) $ L ^ {(} t) ( f ) = ( \mathop{\rm log} _ {r} \sum_{i=0}^ {m-1} p _ {i} r ^ {t l _ {i} } ) / t $, $ 0 < t < \infty $,
3) $ L ^ \prime ( f ) = \max _ {0 \leq i \leq m - 1 } ( l _ {i} - p _ {i} ) $, where it is supposed that in the first two cases the $ p _ {i} $ are the probabilities with which some Bernoullian source generates the corresponding letters of the alphabet $ B _ {m} $( $ \sum_{i=0}^ {m-1} p _ {i} = 1 $), while in the third case, the $ p _ {i} $ are desirable lengths of code words. In the first definition, the cost is equal to the average length of a code word; in the second definition, as the parameter $ t $ increases, the longer code words have a greater influence on the cost ( $ L ^ {(} t) ( f ) \rightarrow L _ {\textrm{ mean } } ( f ) $ as $ t \rightarrow 0 $ and $ L ^ {(} t) ( f ) \rightarrow \max _ {0 \leq i \leq {m-1}} l _ {i} $ as $ t \rightarrow \infty $); in the third definition, the cost is equal to the maximum excess of the length $ l _ {i} $ of the code word over the desired length $ p _ {i} $. The problem of constructing a one-to-one letter-by-letter encoding $ f : B _ {m} ^ {*} \rightarrow B _ {r} ^ {*} $ minimizing the cost $ L ( f ) $ is equivalent to that of minimizing the function $ L ( f ) $ on the sets $ ( l _ {0} \dots l _ {m-1} ) $ of natural numbers satisfying the condition (1). The solution of this problem is known for each of the above definitions of a cost.
Suppose that the minimum of the quantity $ L ( f ) $ on the sets $ ( l _ {0} \dots l _ {m-1} ) $ of arbitrary (not necessarily natural) numbers satisfying condition (1) is equal to $ L _ {r} ( P) $ and is attained on the set $ ( l _ {0} ( P) \dots l _ {m-1} ( P) ) $. The non-negative quantity $ I ( f ) = L ( f ) - L _ {r} ( P) $ is called the redundancy, and the quantity $ I ( f ) / L ( f ) $ is called the relative redundancy of the encoding $ f $. The redundancy of a one-to-one encoding $ f : B _ {m} ^ {*} \rightarrow B _ {r} ^ {*} $ constructed by the method of Shannon for lengths $ l _ {i} $, $ l _ {i} ( P) \leq l _ {i} < l _ {i} ( P) + 1 $, satisfies the inequality $ I ( f ) < 1 $. For the first, most usual, definition of the cost as the average number of code symbols necessary for one letter of the message generated by the source, the quantity $ L _ {r} ( P) $ is equal to the Shannon entropy
$$ H _ {r} ( P) = - \sum_{i=0}^ {m-1} p _ {i} \mathop{\rm log} _ {r} p _ {i} $$
of the source calculated in the base $ r $, while $ l _ {i} ( P) = - \mathop{\rm log} _ {r} p _ {i} $. The bound of the redundancy, $ I ( f ) = L _ {\textrm{ mean } } ( f ) - H _ {r} ( P) < 1 $, can be improved by using so-called coding blocks of length $ k $, in which messages of length $ k $( rather than separate letters) are encoded by the Shannon method. The redundancy of such an encoding does not exceed $ 1 / k $. This same method is used for the effective encoding of related sources. In connection with the fact that the determination of the lengths $ l _ {i} $ in coding by the Shannon method is based on a knowledge of the statistics of the source, methods have been developed, for certain classes of sources, for the construction of a universal encoding that guarantees a definite upper bound on the redundancy for any source in this class. In particular, a coding by blocks of length $ k $ has been constructed with a redundancy that is, for any Bernoullian source, asymptotically at most $ ( ( m - 1 ) / 2 k ) \mathop{\rm log} _ {r} k $( for fixed $ m , r $ as $ k \rightarrow \infty $), where this asymptotic limit cannot be improved upon.
Along with the problems of the effective compression of information, problems of the estimation of the redundancy of concrete types of information are also considered. For example, the relative redundancy of certain natural languages (in particular, English and Russian) has been estimated under the hypothesis that their texts are generated by Markov sources with a large number of states.
In the investigation of problems on the construction of effective noise-immune encodings, one usually considers encodings $ f : B _ {m} \rightarrow B _ {r} ^ {*} $ to which correspond codes $ \{ f ( 0) \dots f ( m - 1 ) \} $ belonging to the set $ B _ {r} ^ {n} $ of words of length $ n $ over the alphabet $ B _ {r} $. It is understood here that the letters of the alphabet of the messages $ B _ {m} $ are equi-probable. The effectiveness of such an encoding is estimated by the redundancy $ I ( f ) = n - \mathop{\rm log} _ {r} m $ or by the transmission rate $ R ( f ) = ( \mathop{\rm log} _ {r} m ) / n $. In the definition of the noise-immunity of an encoding, the concept of an error is formalized and a model for the generation of errors is brought into consideration. An error of substitution type (or simply an error) is a transformation of words consisting of the substitution of a symbol in a word by another symbol in the alphabet $ B _ {r} $. For example, the production of a superfluous line in writing out the figure of a Russian postal index leads to the replacement in the coded word of the symbol 0 by the symbol 1, while the omission of a necessary line leads to the replacement of 1 by 0. The possibility of detecting and correcting errors is based on the fact that, for an encoding $ f $ with non-zero redundancy, the decoding $ f ^ { - 1 } $ can be extended in arbitrary fashion onto the $ r ^ {n} - m $ words in $ B _ {r} ^ {n} $ which are not code words. In particular, if the set $ B _ {r} ^ {n} $ is partitioned into $ m $ disjoint sets $ D _ {0} \dots D _ {m-1} $ such that $ f ( i) \in D _ {i} $ and the decoding $ f ^ { - 1 } $ is extended so that $ f ^ { - 1 } ( D _ {i} ) = i $, then in decoding, all errors that translate a code word $ f ( i) $ in $ D _ {i} $, $ i = 0 \dots m - 1 $, will be corrected. Similar possibilities arise also in the case of other types of error, such as the erasure of a symbol (substitution by a symbol of a different alphabet), the alteration of the numerical value of a code word by $ \pm b r ^ {i} $, $ b = 1 \dots r - 1 $, $ i = 0 , 1 ,\dots $( an arithmetic error), the deletion or insertion of a symbol, etc.
In the theory of information transmission (see Information, transmission of), probabilistic models of error generation are considered; these are called channels. The simplest memoryless channel is defined by the probabilities $ p _ {ij} $ of substitution of a symbol $ i $ by a symbol $ j $. One defines for this channel the quantity (channel capacity)
$$ C = \max \ \sum_{i=0}^ { r-1} \sum_{j=0}^ { r-1} q _ {i} p _ {ij} \ \mathop{\rm log} _ {r} \left ( \frac{ p _ {ij} }{\sum_{h=0}^ {m-1} q _ {h} p _ {hj} } \right ) , $$
where the maximum is taken over all sets $ ( q _ {0} \dots q _ {m-1} ) $ such that $ q _ {i} \geq 0 $ and $ \sum_{i=0}^ {m-1} q _ {i} = 1 $. The effectiveness of an encoding $ f $ is characterized by the transmission rate $ R ( f ) $, while the noise-immunity is characterized by the mean probability of an error in the decoding $ P ( f ) $( under the optimal partitioning of $ B _ {r} ^ {n} $ into subsets $ D _ {i} $). The main result in the theory of information transmission (Shannon's theorem) is that the channel capacity $ C $ is the least upper bound of the numbers $ R $ such that for any $ \epsilon > 0 $ and for all sufficiently large $ n $ there exists an encoding $ f : B _ {m} \rightarrow B _ {r} ^ {n} $ for which $ R ( f ) \geq R $ and $ P ( f ) < \epsilon $.
Another model for the generation of errors (see Error-correcting code; Code with correction of arithmetical errors; Code with correction of deletions and insertions) is characterized by the property that in each word of length $ n $ there occur not more than a prescribed number $ t $ of errors. Let $ E _ {i} ( t) $ be the set of words obtainable from $ f ( i) $ as a result of $ t $ or fewer errors. If for the code
$$ \{ f ( 0) \dots f ( m - 1 ) \} \subset B _ {r} ^ {n} $$
the sets $ E _ {i} ( t) $, $ 0 \dots m - 1 $, are pairwise disjoint, then in a decoding such that $ E _ {i} ( t) \subseteq D _ {i} $, all errors admitting of a model of the above type for the generation of errors will be corrected, and such a code is called a $ t $- error-correcting code. For many types of errors (for example, substitutions, arithmetic errors, insertions and deletions) the function $ d ( x , y ) $ equal to the minimal number of errors of given type taking the word $ x \in B _ {r} ^ {n} $ into the word $ y \in B _ {r} ^ {n} $ is a metric, and $ E _ {i} ( t) $ is the metric ball of radius $ t $. Therefore the problem of constructing the most effective code (that is, the code with maximum number of words $ m $) in $ B _ {r} ^ {n} $ with correction of $ t $ errors is equivalent to that of the densest packing of the metric space $ B _ {r} ^ {n} $ by balls of radius $ t $. The code for the figures of a Russian postal index is not a one-error-correcting code, because $ d ( f ( 0) , f ( 8)) = 1 $ and $ d ( f ( 5) , f ( 8) ) = 2 $, while all other distances between code words are at least 3.
The problem of studying the minimal redundancy $ I _ {r} ( n , t ) $ of a code in $ B _ {r} ^ {n} $ for correction of $ t $ errors of substitution type is divided into two basic cases. In the first case, when $ t $ is fixed as $ n \rightarrow \infty $, the following asymptotic relation holds:
$$ \tag{2 } I _ {2} ( n , t ) \sim t \mathop{\rm log} _ {2} n , $$
where the "power" bound is attained, based on a count of the number of words of length $ n $ in a ball of radius $ t $. For $ t \geq 2 $ the asymptotic behaviour of $ I _ {r} ( n , t ) $ when $ r \geq 2 $ except $ r = 3 , 4 $ for $ t = 2 $, and also when $ r = 2 $ for many other types of errors (for example, arithmetic errors, deletions and insertions), is not known (1987). In the second case, when $ t = [ p n ] $, where $ p $ is some fixed number, $ 0 < p < ( r - 1 ) / 2 r $ and $ n \rightarrow \infty $, the "power" bound
$$ I _ {r} ( n , [ p n ] ) \stackrel{>}{\sim} n T _ {r} ( p) , $$
where $ T _ {r} ( p) = - p \mathop{\rm log} _ {r} ( p / ( r - 1 ) ) - ( 1 - p ) \mathop{\rm log} _ {r} ( 1 - p ) $, is substantially improved. It is conjectured that the upper bound
$$ \tag{3 } I _ {r} ( n , [ p n ] ) \leq n T _ {r} ( 2 p ) , $$
obtained by the method of random sampling of codes, is asymptotically exact for $ r = 2 $, that is, $ I _ {2} ( n , [ p n ] ) \sim n T _ {2} ( 2 p ) $. The proof or refutation of this conjecture is one of the central problems in coding theory.
The majority of the constructions of noise-immune codes are effective when the length $ n $ of the code is sufficiently large. In this connection, questions relating to the complexity of systems that realize the coding and decoding (encoders and decoders) acquire special significance. Restrictions on the admissible type of decoder or on its complexity may lead to an increase in the redundancy necessary to guarantee a prescribed noise-immunity. For example, the minimal redundancy of a code in $ B _ {2} ^ {n} $ for which there is a decoder consisting of a shift register and a single majorizing element and correcting one error has order $ \sqrt n $( compare with (2)). As mathematical models of an encoder and a decoder, diagrams of functional elements are usually considered, and by the complexity is meant the number of elements in the diagram. For the known classes of error-correcting codes, investigations have been carried out of the possible encoding and decoding algorithms and upper bounds for the complexity of the encoder and decoder have been obtained. Also, certain relationships have obtained among the transmission rate of the encoding, the noise-immunity of the encoding and the complexity of the decoder (see [5]).
Yet another line of the investigation in coding theory is connected with the fact that many results (e.g. Shannon's theorem and the upper bound (3)) are not "constructive" , but are theorems on the existence of infinite sequences $ \{ K _ {n} \} $ of codes $ K _ {n} \subseteq B _ {r} ^ {n} $. In this connection, efforts have been made to sharpen these results in order to prove them in a class of sequences $ \{ K _ {n} \} $ of codes for which there is a Turing machine that recognizes the membership of an arbitrary word of length $ l $ in the set $ \cup_{n=1}^ \infty K _ {n} $ in a time having slow order of growth with respect to $ l $( e.g. $ l \mathop{\rm log} l $).
Certain new constructions and methods for obtaining bounds, which have been developed within coding theory, have led to a substantial advance in questions that on the face of it seem very remote from the traditional problems in coding theory. One should mention here the use of a maximal code for the correction of one error in an asymptotically-optimal method for realizing functions of the algebra of logic by contact schemes (cf. Contact scheme); the fundamental improvement of the upper bound for the density of packing the $ n $- dimensional Euclidean space with identical balls; and the use of inequality (1) in estimating the complexity of realizing a class of functions of the algebra of logic by formulas. The ideas and results of coding theory find further developments in the synthesis of self-correcting schemes and reliable schemes of unreliable elements.
References
| [1] | C. Shannon, "A mathematical theory of communication" Bell Systems Techn. J. , 27 (1948) pp. 379–423; 623–656 |
| [2] | E. Berlekamp, "Algebraic coding theory" , McGraw-Hill (1968) |
| [3] | E. Weldon jr., "Error-correcting codes" , M.I.T. (1972) |
| [4] | , Discrete mathematics and mathematical problems in cybernetics , 1 , Moscow (1974) pp. Sect. 5 (In Russian) |
| [5] | L.A. Bassalygo, V.V. Zyablov, M.S. Pinsker, "Problems of complexity in the theory of correcting codes" Problems of Information Transmission , 13 : 3 pp. 166–175 Problemy Peredachi Informatsii , 13 : 3 (1977) pp. 5–17 |
| [6] | V.M. Sidel'nikov, "New bounds for densest packings of spheres in  -dimensional Euclidean space" Math. USSR-Sb. , 24 (1974) pp. 147–157 Mat. Sb. , 95 : 1 (1974) pp. 148–158 -dimensional Euclidean space" Math. USSR-Sb. , 24 (1974) pp. 147–157 Mat. Sb. , 95 : 1 (1974) pp. 148–158 |
Comments
Two standard references on error-correcting codes and coding theory are [a1], [a2].
References
| [a1] | F.J. MacWilliams, N.J.A. Sloane, "The theory of error-correcting codes" , I-II , North-Holland (1977) |
| [a2] | J.H. van Lint, "Introduction to coding theory" , Springer (1982) |
Coding and decoding. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Coding_and_decoding&oldid=55021